From Rules to LLMs: Three Architectures
A side-by-side walk through three architectures for the same simple request, ending with the argument for where in a production system a language model actually earns its place.
Below is the same simple user request, asking for a grade on a homework assignment, walked through three architectures. Step through them. Notice that System 3 is nearly identical to System 1, with one swap. Notice also how System 2, the tempting greenfield default, hands the LLM responsibility for work code already does perfectly.
The lesson sits between Systems 2 and 3. LLMs make things simple. In greenfield it is tempting to give them everything: classification, lookup, formatting, scheduling. Step back and look at the sequence. The parts that were always deterministic are still deterministic. They do not need an LLM in front of them. Use the LLM where it earns its keep, replacing the work code could not do well, and leave the rest alone.
You Have Already Seen This
If you use Claude Code, Cursor, or any AI coding assistant, you have watched function calling happen in real time. You just did not know the name for it.
When Claude Code reads a file, it does not open the file itself. It generates a structured request that says "I want to use the Read tool with the path /src/main.py." The Claude Code runtime receives that request, reads the actual file from disk, and sends the contents back to Claude. Claude then continues the conversation with that new information in context.
When it runs a shell command, the same thing happens. Claude generates a request: "I want to use the Bash tool with the command python test_suite.py." The runtime executes the command, captures stdout and stderr, and sends the output back. Claude reads the test results and decides what to do next.
Every tool in every AI assistant works this way. The model proposes an action, your code executes it, the result goes back to the model. That cycle is the agentic loop, and the rest of this article is about how to build it deliberately.
Who Runs the Loop?
Once the LLM stops trying to do the database's job, two questions follow. Where does the orchestration live? Does this system need function calling at all?
They are not the same question.
The first option is a code orchestrator. Your code receives the request, calls Claude with a prompt asking it to classify the user's intent, parses the response, calls the database, formats the result, and returns it. The LLM is one component in a flow that you wrote. The model never decides what happens next. The flow has no tool definition, no tool_use block, and no tool_result. There is one Claude call, one parsed response, and one SQL query.
This is not really function calling. It is "use Claude as a classifier and call your code yourself." In a bounded request space with a single-shot flow and a tight latency budget, it is leaner than function calling will ever be. You pay for the LLM exactly once per request. You can mock the Claude call in tests with a fixed return value. The orchestration logic is a function with deterministic inputs.
The second option is the canonical function-calling pattern. The LLM is the orchestrator. You define a get_grade(assignment_id) tool, hand the model your full toolset, and let the model decide when to call. The runtime executes the function, the model receives the tool_result, the conversation continues. The control flow is a loop driven by the model's choices, not by yours. This is the System 3 pattern from the diagram above, with the loop made explicit.
It is the right pattern when the request space is open-ended, when one user turn might branch into three lookups, a clarifying question, and a follow-up summary, or when the flow cannot be enumerated in advance. The cost is that Claude sits in the loop on every turn, with the token, latency, and reliability bill that comes with it.
There is a trap inside the trap, and most introductions to function calling skip it. Function calling is offered, not imposed. When you pass get_grade to Claude as a tool, you are letting the model know the tool exists. You are not commanding it to use the tool. The model can decide to invoke it, and the model can also decide to answer from training memory and skip the tool entirely. When that happens, the System 2 antipattern has crawled back inside your agentic loop, this time with the bonus indignity that you wrote a correct function the model declined to call.
The Anthropic API gives you mitigations. Setting tool_choice to {"type": "tool", "name": "get_grade"} forces the model to call a specific tool. {"type": "any"} requires that some tool be called but lets the model pick which. A sufficiently insistent system prompt nudges the model toward tool use without quite forcing it. None of these eliminate the underlying fact that tool dispatch is a probabilistic decision, not a guarantee.
The space between the two options is a spectrum, not a binary. Pure code with no LLM sits at one end. A code orchestrator that calls Claude once for classification sits next to it. An LLM orchestrator with a tight set of deterministic tools sits in the middle. A full agent loop with broad tool access and loose constraints sits at the far end. Workload picks the point. Bounded, deterministic, high-volume, latency-sensitive traffic belongs on the left. Open-ended, conversational, ambiguous traffic belongs further right.
The pattern that quietly wins in production is composition. A code orchestrator inspects each incoming request first, routes the cheap path when the request matches a known shape, and engages Claude only for the long tail. The model never sees the deterministic eighty percent of traffic. When it does see a request, it has tools, it does its tool-calling job, and the system pays the LLM bill on the long-tail twenty percent instead of on every request. This is the architecture you arrive at when you take both options seriously and refuse to pick one.
From Toy to Production: The Pattern
Before walking through a concrete production example, it is worth pausing to define the vocabulary the next section assumes. The terminology comes from cloud computing rather than from language models, and it sits at a different abstraction level than anything earlier in this article. Two concepts are central: a Lambda and a Step Function. Both are AWS terms, but the patterns they describe exist on every major cloud provider, and the architectural argument that follows is portable.
Serverless is the foundation. A serverless platform is one where the developer writes a function, hands it to the cloud provider, and the provider takes responsibility for everything underneath: provisioning, scaling, patching, capacity planning, and machine-level operations. The developer never sees a server and never tunes a load balancer.
When a request arrives, the platform allocates compute on the fly, runs the function, returns the result, and tears the compute down. You pay for the time the function actually ran, often measured in milliseconds, rather than for an idling instance. The economics favor workloads that are bursty, infrequent, or wildly variable in load. The operational story favors teams that would rather ship code than tune CloudWatch alarms.
Lambda, in this context, is AWS's name for the serverless function product. A single Lambda is a small unit of code, often dozens of lines, with a defined input shape and a defined output shape. It runs in response to triggers such as an HTTP request, a queue message, a scheduled timer, or an upstream service invoking it.
Each Lambda has one responsibility. A Lambda that calls Bedrock to extract structured intent from free-text input has nothing else in it: no retry logic, no routing, no awareness of the caller. Microsoft Azure calls the equivalent product Azure Functions, and Google Cloud calls it Cloud Functions. The shape and the discipline are the same on each platform: small, single-purpose, stateless functions, ideally written so they can be invoked from many contexts without modification.
Step Functions is AWS's serverless orchestration service. Where a Lambda is a unit of work, a Step Function is the workflow that strings units of work together. The workflow itself is declared in a JSON document, with named states, transitions between states, retry policies, error catches, parallel branches, and conditional routing.
The Step Functions runtime executes the workflow, invokes Lambdas (and other AWS services) at the appropriate moments, and tracks every transition in an execution history that remains queryable after the fact. Azure offers two services that play this role, Durable Functions and Logic Apps, and Google Cloud offers Workflows. The exact syntax differs across platforms; the architectural shape, a state machine that coordinates leaf operations, does not.
The combination of these primitives is a recognized pattern in distributed systems literature, often referred to as serverless microservices with externalized orchestration. The pattern is not arbitrary. It is the production realization of the architecture argued for earlier in this article: each Lambda is a microservice doing one thing, the state machine is the deterministic code orchestrator from the previous section, and the LLM is constrained to leaf Lambdas where its strength lives.
All three lessons compose into one architecture: microservices give independent deployability and reuse, serverless gives scale-to-zero pricing and elastic capacity, and state-machine orchestration gives the BPMN-style choreography (retries, backoff, routing, parallel execution, error handling) declared once in JSON rather than scattered across application code.
That last point matters more than it sounds. When orchestration concerns live inside application code, every Lambda has to know about retry policy, error categorization, and what runs before and after it. The code accretes a layer of plumbing that is hard to test, reuse, and reason about.
Pulling that plumbing out into a state machine reverses each of those properties. Lambdas become testable as pure functions: pass a JSON payload, assert on the JSON returned. Because they no longer assume any particular caller, they also become reusable across workflows. The state machine itself becomes the single declarative document that captures the system's flow, reviewable in a pull request, diffable across versions, and observable through a single dashboard.
The next section walks through a small Step Function definition that does exactly what the toy example demonstrated, in production-grade form. The structural argument from the toy example, that the LLM should sit at the edges of a deterministic flow rather than at the center of one, holds at this scale. The vocabulary is just heavier.
A State Machine Holds the Loop
The toy example in this article uses a single user request and a single LLM call. Real systems are larger, and the same architectural choice scales with them. One concrete production shape is worth naming because it shows the pattern at industrial weight.
A serverless state machine, AWS Step Functions in this case, owns the orchestration. The state machine is a JSON definition with named states, transitions, retry policies, timeouts, and conditional branches. It runs the same way every time. It is, in the precise sense, the deterministic code orchestrator from the previous section, just written in a workflow DSL instead of Python or TypeScript.
Inside the state machine, individual states invoke Lambdas. Two are enough to make the point. One Lambda calls an LLM through Amazon Bedrock to extract structure from messy input: the prompt is well-defined, the tool is the right one for ambiguity, and the Lambda returns the model's output to the state machine. The second Lambda calls a deterministic third-party API, perhaps a transcription service, a vector store, or an internal microservice. Each Lambda has one job. The Lambdas do not know about each other, about retry policy, or about routing. Each receives a small JSON payload, does one thing, and returns.
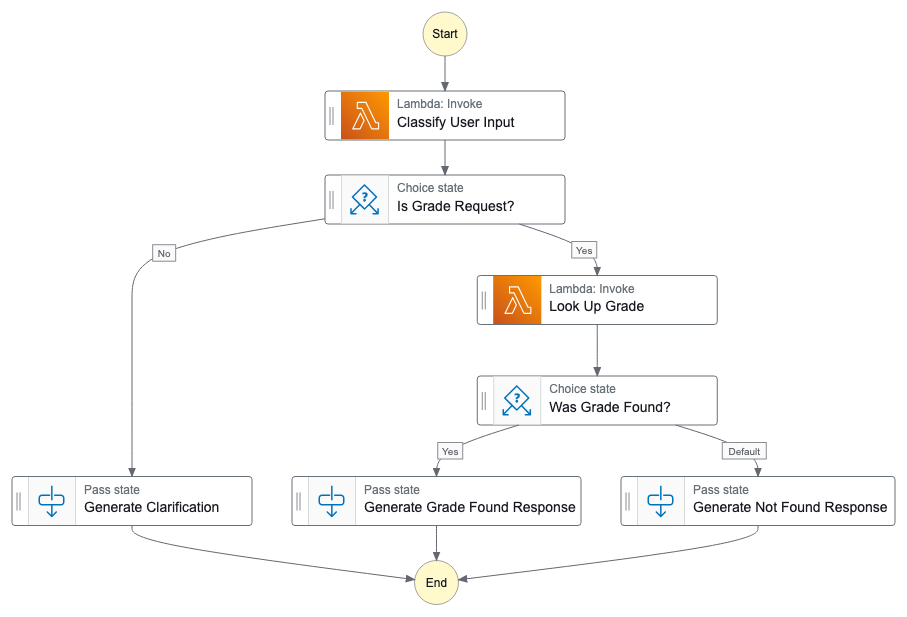
The state machine handles the BPMN-style choreography that would otherwise live inside application code: retries with exponential backoff configured per state, choice states that branch on the prior step's output, parallel states that fan out and rejoin, catch blocks that route specific errors to recovery states, and timeouts at every level. None of this lives inside the Lambdas, and none of it is the LLM's responsibility.
The payoff is what falls out of the separation. The Lambdas become small, single-purpose, and trivially testable: pass them a JSON payload, assert on the JSON they return. They are also reusable, since the same LLM-extraction Lambda can be invoked from a different state machine with a different retry policy and no code change. The state machine, meanwhile, gets its own visibility surface in CloudWatch and the Step Functions console, so a failed run shows you exactly which state errored, on which input, after how many retries. An LLM-orchestrated agentic loop cannot produce that picture; the model's "decision to retry" is opaque, and its decision to skip a step entirely is, as the previous section noted, always available to it.
The architecture is orthogonal in the engineering sense. The state machine knows nothing about how the Lambdas do their work; the Lambdas know nothing about what runs before or after them. Swapping Bedrock for a self-hosted model or a different vendor's API touches one Lambda and nothing else. Adding a new parallel branch or a new validation step touches the state machine and nothing else. The system extends additively. New capability does not require existing capability to be disturbed, which is the difference between a codebase that grows comfortably for years and one that ossifies in months.
Azure Durable Functions and Logic Apps offer the same shape, as does GCP Workflows. The argument is portable. The architecture wins for the same reason in each case: control flow externalized, microservices kept narrow, the LLM constrained to leaf operations where its strength lives.
What Goes Wrong
Function calling is a text generation task. The model is predicting the next token, same as always. It just happens to be predicting tokens that form JSON. Every failure mode of text generation applies, regardless of whether the loop runs inside a single API call or inside a multi-step state machine.
Hallucinated Functions
The model calls a function that does not exist. You provided get_student_grade and list_assignments, and the model calls search_grades. This typically happens when the user's request does not map cleanly to any available tool, and the model invents one rather than admitting it cannot help.
Validate every function name against your tool registry before execution. It sounds obvious, but production systems miss it regularly.
Schema Violations
The model calls the right function with the wrong arguments: missing required fields, wrong types, values outside the specified enum. Validate arguments against the schema before execution. Anthropic also offers strict mode: add "strict": true to your tool definition and the API guarantees the output conforms to your schema exactly. No type mismatches, no missing fields. This is the simplest fix for schema violations in production.
Infinite Loops
The model calls a function, receives a result, then calls the same function again with the same arguments. Or it alternates between two functions endlessly. This happens most often when the function result is ambiguous or does not contain information the model can use to make progress.
Set a maximum number of tool-call turns. Three to five is typical for simple applications. If the model has not produced a text response after that many rounds, break the loop and ask the model to respond with what it has.
Missing Information
If the user's prompt does not include enough information to fill all required parameters, Claude's behavior depends on the model. Claude Opus is more likely to ask the user for the missing information. Claude Sonnet and Haiku are more likely to guess a reasonable value and proceed.
If a student asks "What's my grade?" without specifying which assignment, Sonnet might guess the most recent one. Opus would more likely ask "Which assignment would you like me to look up?" If you want all models to ask rather than guess, include the instruction in the system prompt explicitly.
The Execution Gap
There is a fundamental asymmetry in function calling that is easy to miss. The model proposes. Your code disposes.
The model has no way to know if a function succeeded, what it returned, or whether the arguments were valid, until you tell it. This creates a gap between what the model believes happened and what actually happened. Managing this gap is where most of the engineering effort lives.
When a function fails, you have a choice. You can return an error message and let the model retry with different arguments, return a graceful fallback, or hide the error entirely and substitute a default. Each choice changes how the conversation evolves, and there is no universal right answer.
What matters is that you make the choice deliberately. Unhandled exceptions that crash the tool execution loop and return nothing leave the model confused, often causing it to hallucinate a result or loop indefinitely. Every tool call should return structured status, and every failure should be reported in a form the model can interpret.
The Anthropic API also lets you mark a tool result as an error explicitly with the is_error flag on the tool_result block. The model can then inform the user, ask for corrected input, or try a different approach. The flag is small, but it keeps the gap between what the model believes happened and what actually happened narrow rather than wide.
Where This Fits
Function calling is a primitive, not a product. It is the mechanism that makes everything else possible.
Claude Code uses function calling to read files, run commands, edit code, and search a codebase. Each of those capabilities is a tool definition. The Claude Code runtime is the loop.
Agent frameworks like LangChain, CrewAI, and the Anthropic Agent SDK are orchestration layers built on top of this primitive. They add memory, multi-agent routing, retries, and workflow management. Underneath, they are all running the same loop: define tools, send messages, execute tool calls, return results.
The Model Context Protocol, MCP, is a standard for sharing tool definitions across applications. An MCP server exposes tools and an MCP client converts them to the provider's format and plugs them into the loop. The protocol is about interoperability, not mechanism.
Understanding the loop is like understanding HTTP before using Django, or understanding SQL before using an ORM. You could skip it and work at the framework level. But when something breaks, and something always breaks, you will not be able to debug it without understanding what is happening underneath.
Before Function Calling
It is worth understanding what function calling replaced, because the old approach explains why the new one matters.
Before 2023, connecting an LLM to external systems meant parsing free-form text. You would prompt the model to output an action keyword followed by arguments, then write a regex to extract the action and the arguments from the model's output. It worked, barely. The model might format the output slightly differently each time, add explanatory text before the action, or use quotes inconsistently. Every edge case required another regex rule.
Toolformer, the 2023 paper from Meta AI, was one of the first to show that models could be trained to generate structured tool calls reliably. The key insight was that you could fine-tune a model on examples of tool use, and it would learn when to invoke a tool and how to format the call correctly.
Function calling replaced regex parsing with schema validation, replaced hoping the model formats things correctly with a structured protocol both sides understand, and turned LLMs from text generators that had to be scraped into orchestration engines with a clean interface.
That interface is what makes agents possible.
References
- Anthropic. (2025). "Tool use with Claude." Anthropic Documentation.
- Anthropic. (2025). "Structured Outputs." Anthropic Documentation.
- Anthropic. (2025). "Agent SDK." Anthropic Documentation.
- Schick, T., et al. (2023). "Toolformer: Language Models Can Teach Themselves to Use Tools." arXiv.
- Patil, S., et al. (2023). "Gorilla: Large Language Model Connected with Massive APIs." arXiv.
- Qin, Y., et al. (2023). "ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs." arXiv.